Details
We provide a large-scale video-language pre-training dataset (Auto-captions on GIF) for this challenge. Here we show some GIF video examples and the corresponding captions in our Auto-captions on GIF dataset as following:
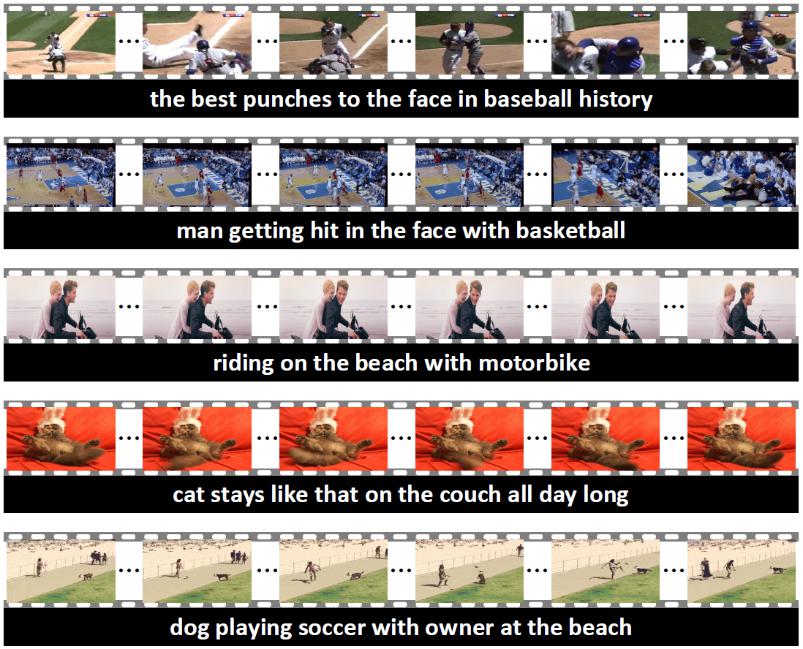
To formalize the task of pre-training for video captioning, we provide three datasets to the participants:
A pre-training dataset of 163183 GIF videos and 164378 sentences in Auto-captions on GIF. The vocabulary size of our dataset is 31662.
A training dataset of ~9.5K videos in MSR-VTT. Each video is annotated with 20 captions.
A validation dataset of ~0.5K videos in MSR-VTT. Each video is annotated with 20 captions.
In addition to the datasets above, we will adopt a testing set for evalutaion.